In this guide, you’ll discover the fundamental principles of web scraping and how to embark on your web scraping journey. It encompasses essential concepts and serves as a tutorial to initiate your exploration of web scraping with Apify.

Table of Contents
Web Scraping Basics
Web scraping is a method employed to retrieve data and content from web pages, primarily utilizing bots. This technique allows the extraction of either all or specific data, depending on the user’s requirements. Typically, the scraped data is exported in the form of a spreadsheet or an API. The process involves making HTTP requests, performing HTML parsing, and finally, extracting the desired data.
Initiating Your Web Scraping Journey
Several methods can kickstart your venture into web scraping. Utilizing web scraping APIs, libraries, and tools proves to be efficient in this regard, streamlining the web scraping process.
Key Elements of Web Scraping
- HTTPS Requests: Bots acquire web page data through a GET request, but it’s crucial to note that not all websites permit data scraping. The obtained response grants access to the data for scraping.
- Data Extraction from HTML Code: After receiving the HTTP response, data extraction from the HTML code becomes possible. HTML parsing may be necessary, and this can be efficiently achieved using parsing libraries such as Beautiful Soup, xlml, or pyquery.
- Data Storage: Once unstructured data is extracted, it needs to be organized for proper use. Structuring and storing data can be accomplished through CSV or JSON files, making it suitable for various applications. Alternatively, cloud storage infrastructures like AWS S3, Google Cloud, or Fermyon Cloud can be employed for data storage.
Navigating Web Scraping with Apify
Web scraping becomes more accessible with platforms like Apify. Apify serves as a comprehensive platform for constructing, deploying, and monitoring web scrapers and data extraction tools. With Apify, you can create bots to scrape data from web pages. This guide illustrates how to utilize Apify for data extraction using a pre-built web scraper, avoiding the need to build one from scratch. Apify offers a variety of pre-existing scrapers for users, enhancing the efficiency of the web scraping process.
- Sign up for an Apify account: To begin, the initial step is to create an Apify account. This is your starting point, and it’s worth noting that obtaining an account with Apify is free. You also have the option to upgrade your plan later for additional features.
- Exploring your Dashboard: Once your Apify account is established, your journey commences. Your dashboard presents an array of web automation tools, boasting a selection of over 1000 options. Depending on the specific data you intend to scrape, you can choose any tool from this extensive collection.
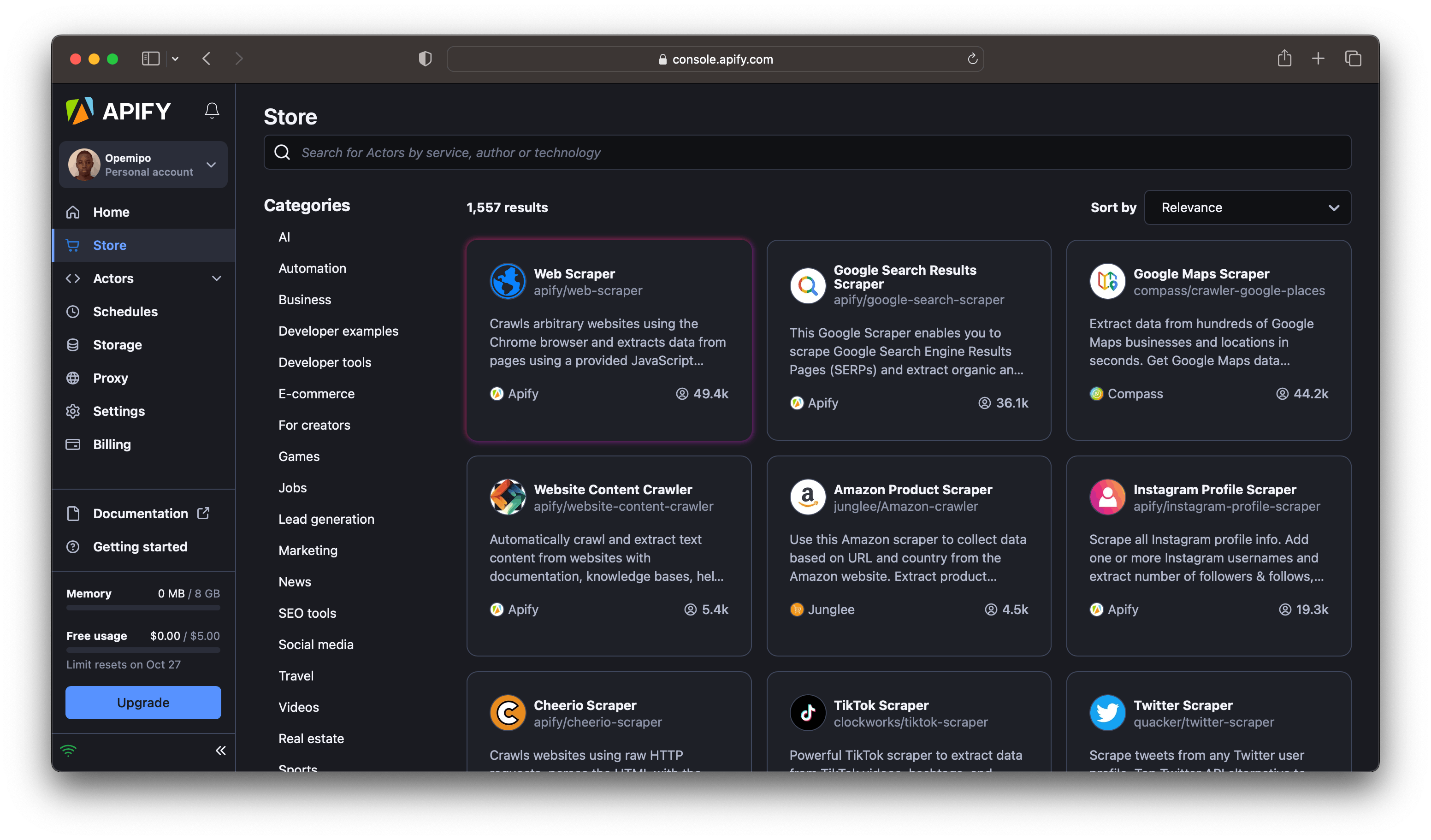
- Utilizing the ‘Web Scraper’ actor: To keep this article user-friendly, we’ll be employing the ‘Web Scraper’ actor. This actor functions by loading URLs in your browser and executing a page function to extract data from the specified website. This process allows for the extraction and exportation of data in the desired format.
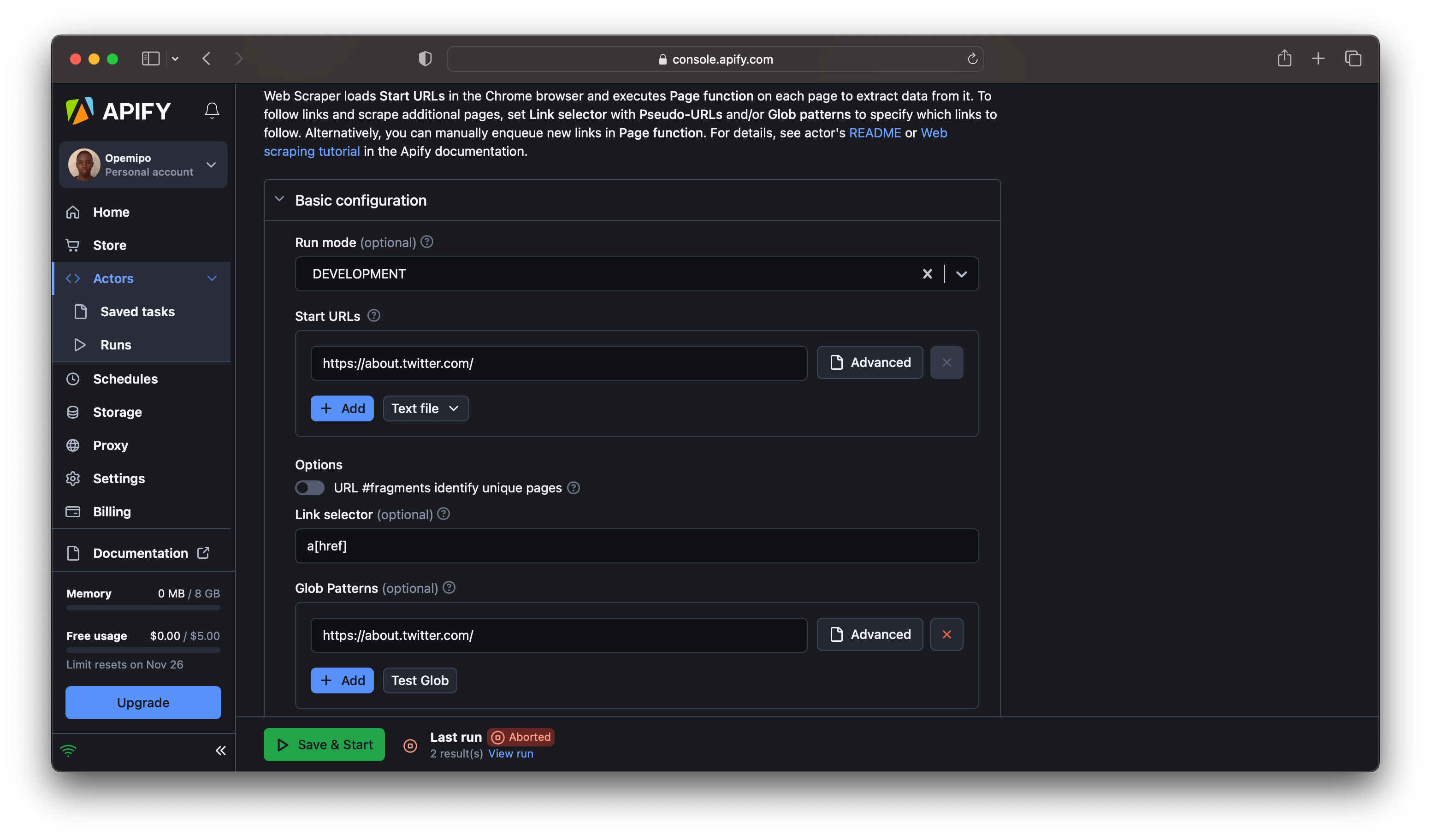
- On the input tab of the ‘Web Scraper’ actor, you’ll encounter a Basic Configuration panel. Your task here is simple – modify the start URL and Glob patterns to match the URL from which you wish to extract data. For instance, in this demonstration, we’ll use Twitter’s About webpage. You can observe the setup in the accompanying image:
 After completing these steps, proceed to click the “Save and Run” button located on the dashboard. This action will direct you to the logs panel, providing insights into how the data extraction process is unfolding. For exporting the extracted data in a structured format, head to the storage panel. There, you have the option to save your data in various formats such as CSV, XML, JSON, and several others. This concludes the initial phase of your web scraping journey.
After completing these steps, proceed to click the “Save and Run” button located on the dashboard. This action will direct you to the logs panel, providing insights into how the data extraction process is unfolding. For exporting the extracted data in a structured format, head to the storage panel. There, you have the option to save your data in various formats such as CSV, XML, JSON, and several others. This concludes the initial phase of your web scraping journey.
Conclusion
This serves as one of the most accessible routes for individuals interested in delving into web scraping. The approach is intentionally not overly technical, providing a brief guide on initiating web scraping endeavors. While Apify offers numerous technical aspects to explore, this article remains introductory in nature. I trust you found it informative and helpful. Stay tuned for my upcoming articles—I look forward to sharing more insights with you!